
自社サーバーやクラウドに格納したデータベースを加工・集計する際には、多くの場合SQL文を記述しなくてはなりません。
しかし、KNIMEを使えばグラフィカルな操作画面でデータベースからデータを抽出でき、しかも加工・集計・出力までSQLコーディングは不要です。
今回は「データベースから情報を抽出して、KNIMEに読み込ませるまで」の流れを解説します。
データベースから全てのレコードをダウンロードするだけなら簡単なフローで作れますが、膨大な読み込み時間とRAM(メモリ)に大きな負荷がかかります。
KNIMEではローカルPCにダウンロードする前にデータベース上でテーブルを扱いやすい形式に加工できます。必要な形に加工し軽量化するとローカルPCに連携するデータボリュームを削減して負荷を軽減するコツをつかみましょう。
この記事では加工のコツや実務例を踏まえて説明していきます。
データベースからデータを取得するステップ
まず、データベースからデータを取得するまでの大まかな流れをみてみましょう
- コネクターでデータベースを指定
- テーブルを指定
- 複数のテーブルを繋いだり、フィルターを掛けたり、グループ化をするなどの加工
- KNIMEに読み込み
1. コネクターでデータベースを指定
接続元となるデータベースとKNIMEを接続するために
KNIMEでデータベースと接続するノードはNode Repository(画面左側のノード一覧)からDB Connectionカテゴリに接続元の種類ごとに格納されています。
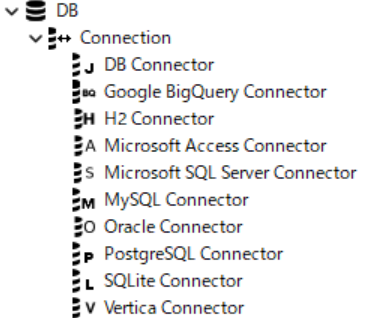
Google Bigquerryとの接続方法は、こちらの記事で詳しく説明しているのでご覧ください。
もし、必要なコネクターノードがなければ、KNIME Extensionからダウンロードできるかもしれません。
「(接続したいデータベース名) connector KNIME」で検索してみてください。
2. テーブルを指定
DB ConnectorでデータベースとKNIMEの接続を確立出来たら、DB Table Selectorをとつなぎます。
接続後、必要なテーブルを設定画面で選択します。
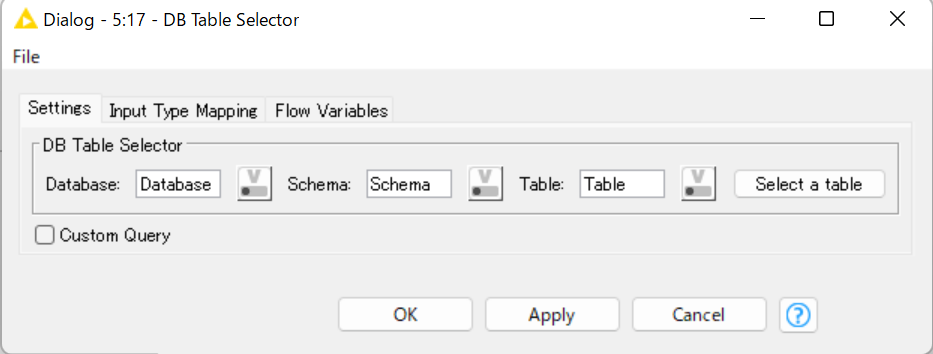
画像中の”Select a table”クリックすると、接続されているデータベースのディレクトリが表示されるので、接続したいテーブルを選択してください。
筆者の経験上、Microsoft SQL serverでは問題なく上記の手順でテーブルを指定できますが、Google Bigqueryとの接続時はエラーが発生してしまうことがあり、その場合には”Costom Query”にチェックを入れ、手書きでテーブルを指定します。
手書きといっても、ここではテーブルを指定できればいいので、以下のようにテーブル内を全件指定して大丈夫です。
|
1 2 3 4 |
SELECT * FROM 'Schema.Table' |
※Schemaにスキーマ名、Tableにテーブル名を置き換えてください。
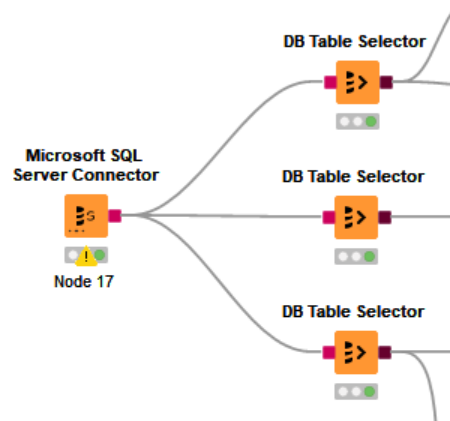
この工程を必要なテーブルの分繰り返します。
KNIMEは1つのノードに複数のノードを接続できますので、前項で作成したServer Connectorに必要な分のTable Secelctorをつなげていきましょう。
3. 複数のテーブルを繋いだり、フィルターを掛けたり、グループ化をするなどの加工
KNIMEに読み込む際にデータ量が大きいと、読み込みに膨大な時間とサーバー・PC双方の処理能力に多大な負荷がかかるので、このステップではデータ量を減らすために加工します。
元々データボリュームが小さかったり、サーバーやPCの能力に余力がある場合には、このステップを省略してローカルPCにダウンロードされてから処理もできます。
ここで使う4つの主なノードを紹介します。
DB GroupBy(指定のカラムをグループ化)
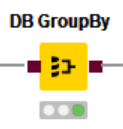
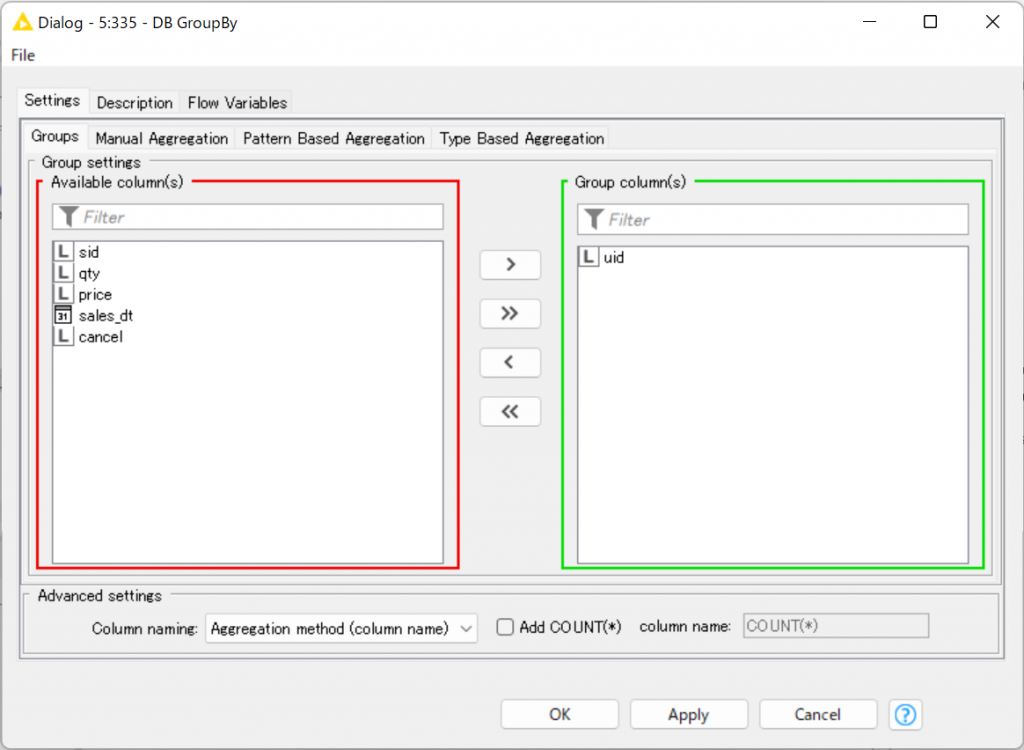
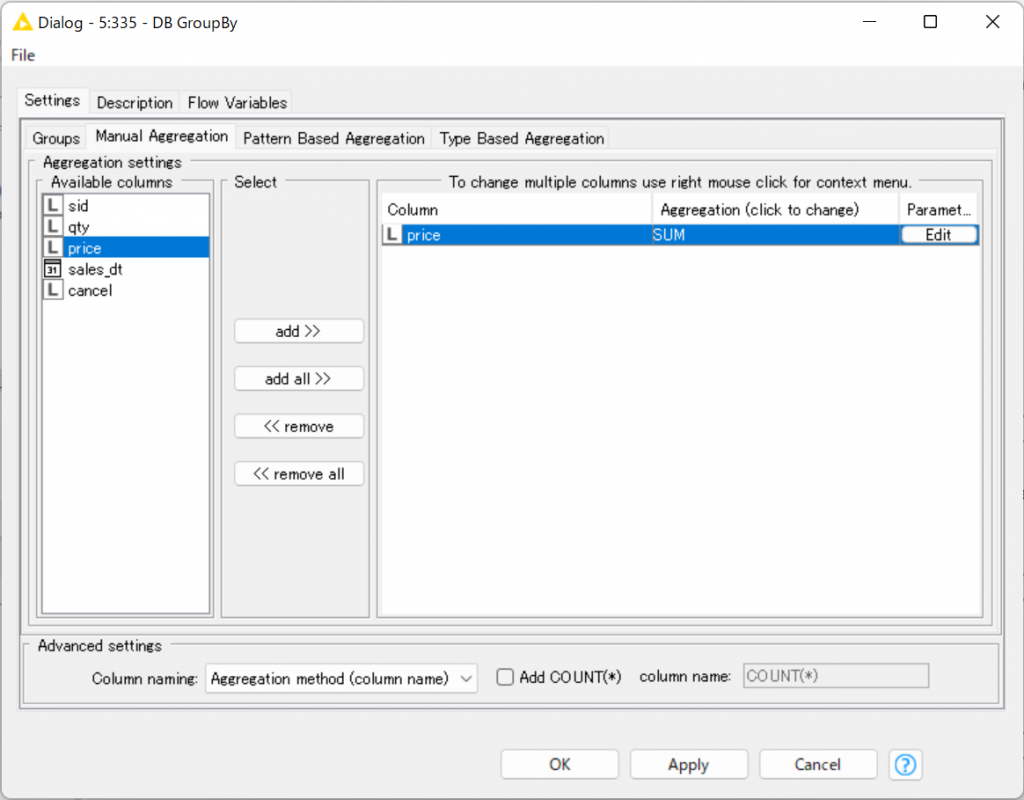
SQLのGROUP BYをするノードで、指定したカラム(画像では”uid”)をキーとして、他のカラムを集約します(画像では、”price”の合計を計算)。
DB Column Filter(列をフィルタ)
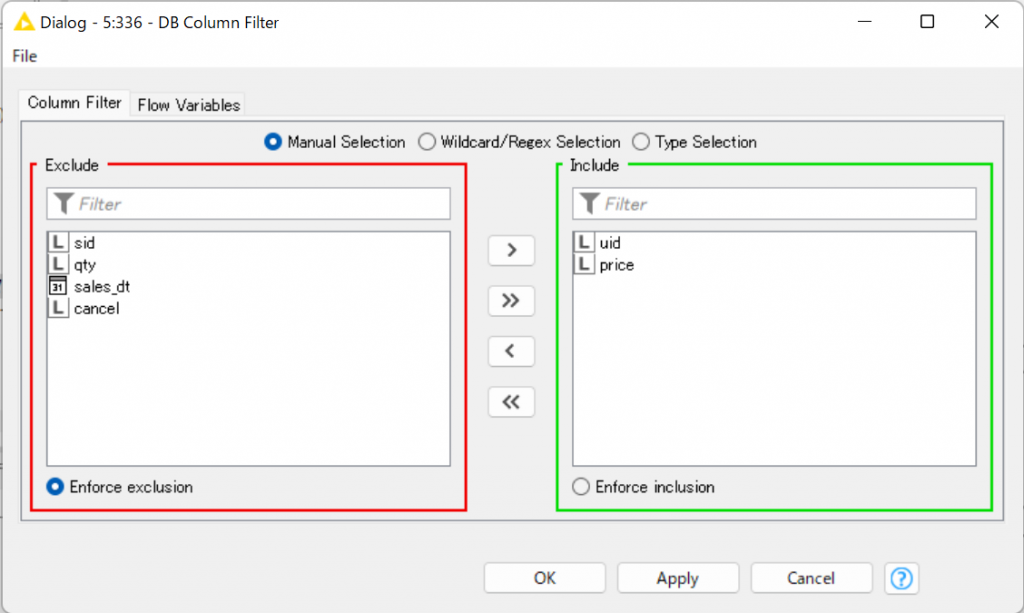
必要なカラムだけを抽出します。
画像では、”uid”と”price”だけを抽出し、他のカラムはこれ以後には含まれなくなります。
DB GroupByでも同じことができますが、好みで使い分けていいと思います。
DB Row Filter(行・レコードをフィルタ)
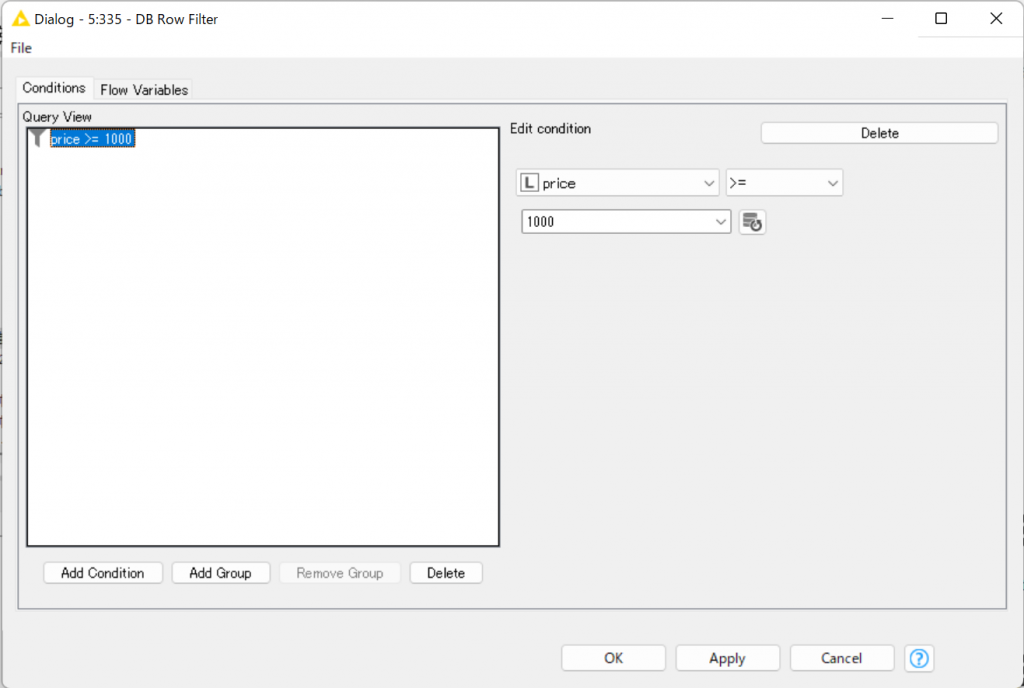
レコードを特定の条件に合わせて抽出・除外します。
画像では、”price”が1000以上のレコードを抽出しています。
DB Joiner(テーブル同士を結合)
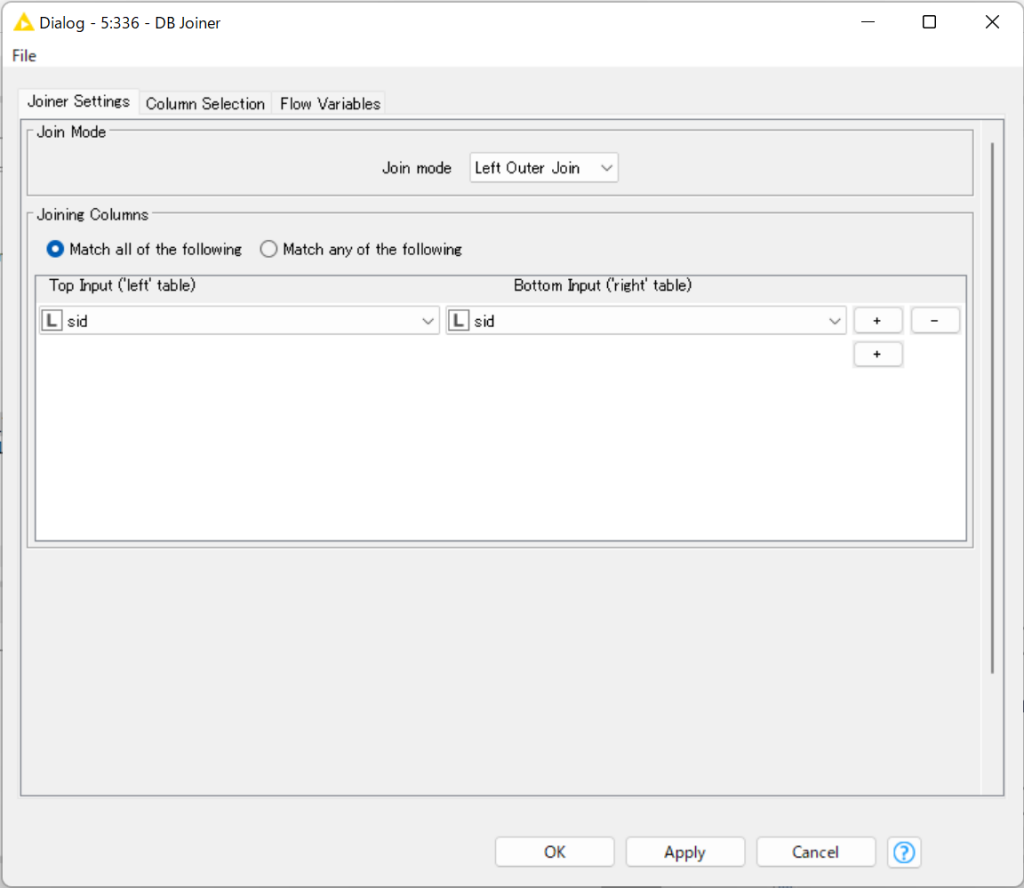
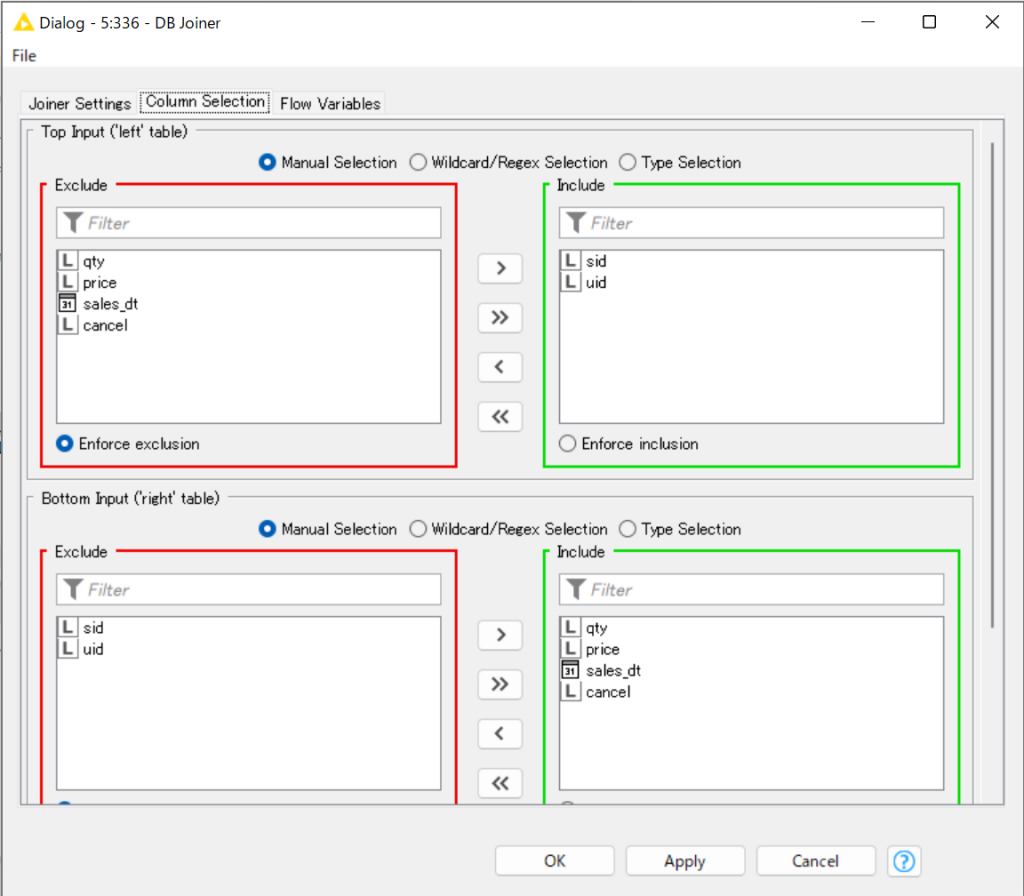
テーブル同士を結合します。
画像では、”uid”が同じものを左外部結合しています。
同じServer Connectorから派生したもの同士でないと結合できないことに注意してください。
正確にはデータを軽くする処理ではありませんが、後述のステップで複数のテーブルをそれぞれローカルPCにダウンロードするよりも、1つにまとめて読み込んだほうが結果として処理効率が高まります。
4. KNIMEに読み込み
ここまでの処理は、あくまでもデータベース上で行われており、ローカルPCに読み込むことでさらなる加工・集計をしたり、他のデータベースやExcelファイルなどと接続できるようになります。
使うノードは DB Reader
このノードは読み込みたいノードにつなぐだけで、設定しなくても動作します。
この時点でデータベースからローカルPCにデータの所在は移動しています。
DB Reader実行後に、実行完了したノードにつながるの”DB Joiner”などのノードに変更を加えると、読み込みがリセットされてしまい、都度読み込みが必要になるので、できればDB Reader実行前に正しいデータの形になっているか確認しておきましょう。
KNIMEに読み込んだ後は、KNIMEで加工集計してもいいですし、CSVに出力して、Microsoft AccessやPowerPivot、PowerBIなどの使い慣れたツールにインポートして分析してもいいでしょう。
コツと注意点
ここまで解説した内容で、データベースからKNIMEにデータインポート出来るようになっていますが、知っておくと便利なコツや注意点を挙げていきます。
DBノードではプレビューで全件表示できない。
KNIMEは処理中のノードでも、そこまでの処理をプレビュー表示できます。
しかし”DB ~”ノードでは該当するすべてのレコードではなく、何行分表示するかを選択して表示するようになっています。しかも、読み込むたびにある程度の時間がかかります。
慣れないうちは、1つのノードを実行するたびにプレビュー表示して、想定通りのテーブルに加工されているか確認しましょう。
SQL文でどのような処理がされているか確認できる
KNIMEのDBノードは、その時点までの処理をSQL文で記述したコードが見られます。
ただし、カラムにすべてテーブル名がついていたり、改行が少なかったりと非常に読みにくいため、あまり使う機会はないでしょう。
ノードの左右のポートは同じ色・形状にしか接続できない
今回でてきたのは、
- 赤い四角(DB 情報を渡す)
- 暗赤色の四角(DB上のテーブル情報を渡す)
- 黒い三角(KNIME上でのテーブル情報を渡す)
の3つでしたが、
他にも、青い四角や赤枠の四角もあります。
これらは同じ色・形にしか接続できず、例えばServer Connectorの赤い四角からDB GroupByの暗赤色の四角に接続はできません。
まとめ
近年、「ノーコード開発」という言葉をよく聞くようになりました。
エンジニアでない例えばマーケターや経営戦略担当者も、KNIMEを使って「ノーコードデータベース操作」を身に着けることで迅速な判断ができるようになりますね。